
Benchmark de inferência de IA Procyon® para Android 
Desempenho e qualidade do benchmark de IA usando API de redes neurais
O aprendizado de máquina está potencializando novos recursos interessantes em aplicativos móveis. Muitos dispositivos agora têm hardware dedicado para acelerar as operações intensivas computacionalmente necessárias para inferência no dispositivo. A API de redes neurais (Neural Networks API, NNAPI) Android fornece uma camada base para estruturas de aprendizado de máquina para acessar o hardware de processamento de IA dedicado em um dispositivo.
O Benchmark de inferência de IA do Procyon para Android mede o desempenho de IA de dispositivos Android usando API de redes neurais. A pontuação de benchmark reflete a velocidade e a precisão das operações de inferência no dispositivo. Com o Benchmark de inferência de IA do Procyon para Android, você não apenas pode medir o desempenho do hardware de processamento IA dedicado em dispositivos Android, mas também pode verificar a qualidade da implementação da API de redes neurais.
O benchmark usa uma variedade de redes neurais populares e de última geração em execução no dispositivo para executar tarefas comuns de visão de máquina. O benchmark é executado no hardware de processamento de IA dedicado do dispositivo por API de redes neurais. O benchmark também executa cada teste diretamente na GPU e/ou CPU para comparação.
Recursos
- Testes baseados em tarefas comuns de visão de máquina usando redes neurais de última geração.
- Mede o desempenho da inferência e a qualidade da saída.
- Compare o desempenho de API de redes neurais, CPU e GPU.
- Verifique a implementação e a compatibilidade de API de redes neurais.
- Otimize drivers para aceleradores de hardware.
- Compare o desempenho do modelo otimizado para float e integer.
- Simples de configurar e usar em um dispositivo ou por ADB.
Desempenho e qualidade de API de redes neurais
Com o Benchmark de inferência de IA do Procyon para Android, você pode medir o desempenho do hardware de processamento de IA dedicado e verificar a qualidade da implementação de API de redes neurais com testes baseados em tarefas comuns de visão de máquina.
Projetado por profissionais
Criamos o Benchmark de inferência de IA do Procyon para Android para equipes de engenharia que precisam de ferramentas padronizadas e independentes para avaliar o desempenho geral de IA de implementações de API de redes neurais e hardware móvel dedicado.
Rápido e fácil de usar
O benchmark é fácil de instalar e executar, sem necessidade de configuração complicada. Execute o benchmark no dispositivo ou por ADB. Veja pontuações de benchmark, gráficos e classificações no aplicativo ou exporte arquivos de resultados detalhados para análise posterior.
Desenvolvido com experiência no setor
Os benchmarks Procyon são projetados para uso industrial, empresarial e de imprensa, com testes e recursos criados especificamente para usuários profissionais. O Benchmark de inferência de IA para Android foi projetado e desenvolvido com parceiros do setor por meio do Benchmark Development Program (BDP) UL. O Benchmark Development Program é uma iniciativa da UL Solutions que visa criar benchmarks relevantes e imparciais, trabalhando em cooperação com os membros do programa.
Modelos de rede neural
MobileNet V3

O MobileNet V3 é um modelo compacto de reconhecimento visual criado especificamente para dispositivos móveis. O benchmark usa o MobileNet V3 para identificar o assunto de uma imagem, usando uma imagem como entrada e gerando uma lista de probabilidades para o conteúdo da imagem. O benchmark usa a grande variante minimalista do MobileNet V3.
Inception V4

O Inception V4 é um modelo de última geração para tarefas de classificação de imagens. Projetado para precisão, é um modelo muito mais amplo e profundo que o MobileNet. O benchmark usa o Inception V4 para identificar o assunto de uma imagem, usando uma imagem como entrada e gerando uma lista de probabilidades para o conteúdo identificado em tal.
SSDLite MobileNet V3
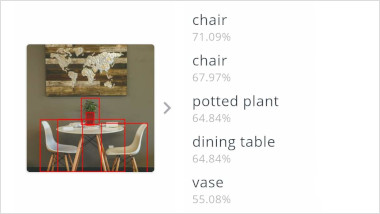
SSDLite é um modelo de detecção de objetos que visa produzir caixas delimitadoras em torno de objetos em uma imagem. O SSDLite usa o MobileNet para extração de recursos para permitir a detecção de objetos em tempo real em dispositivos móveis. No benchmark, a versão float do SSDLite usa a pequena variante minimalista MobileNet V3. A versão integer usa a variante EdgeTPU do MobileNet V3.
DeepLab V3

O DeepLab é um modelo de segmentação de imagens que visa agrupar os pixels de uma imagem que pertencem à mesma classe de objeto. A segmentação semântica de imagens rotula cada região da imagem com uma classe de objeto. O benchmark usa o MobileNet V2 para extração de recursos, permitindo inferência rápida com pouca diferença de qualidade em comparação com modelos maiores.
CNN personalizada
O benchmark inclui uma Rede Neural Convolucional (Convolutional Neural Network, CNN) personalizada baseada na arquitetura AlexNet. Ele é projetado para testar o desempenho de operações básicas de CNN e é treinado em dados de treinamento gerados aleatoriamente. Ele contém duas camadas convolucionais, que são seguidas pelas camadas Max Pooling e Dropout, e uma camada totalmente conectada.
Modelos integer e float
O benchmark inclui versões otimizadas para float e integer de cada modelo. Cada modelo é executado em todos os hardware compatíveis no dispositivo. Com API de redes neurais, o benchmark usará o hardware de processamento de IA dedicado do dispositivo, se suportado. Os modelos float usam API de redes neurais ou são executados diretamente na CPU ou GPU. Os modelos inteiros usam API de redes neurais ou são executados diretamente na CPU.
Resultados e insights
Pontuações de benchmark
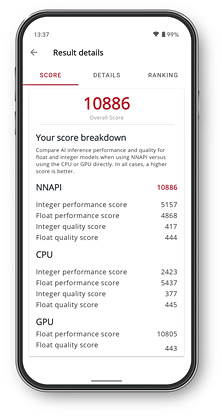
Teste dispositivos e processadores e compare desempenho e qualidade com modelos inteiros e flutuantes.
Gráficos de desempenho
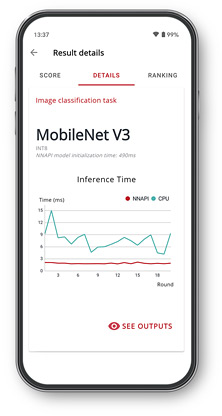
Um gráfico para cada modelo mostra o tempo de inferência usando API de redes neurais e quaisquer outros processadores disponíveis.
Monitoramento de hardware
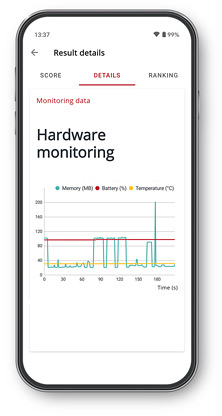
Veja como a temperatura, o nível de carga da bateria e o uso da memória mudaram durante a execução do benchmark.
Saídas do modelo
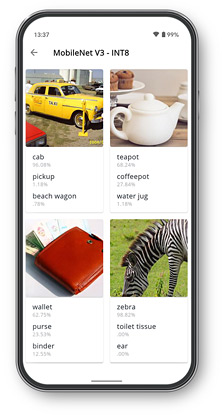
Verifique as saídas de cada modelo para garantir que o acelerador esteja retornando os resultados corretos.
Classificação do dispositivo
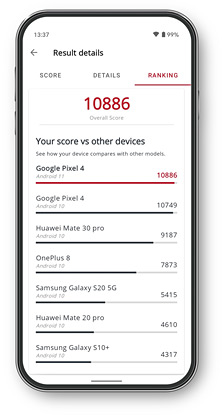
Veja como seu dispositivo se compara a outros modelos na lista de classificação de desempenho no aplicativo.
Licença da unidade
Get quote Press license Request trial- Site license anual para Benchmark de inferência de IA do Procyon para Android.
- Número ilimitado de usuários.
- Número ilimitado de dispositivos.
- Suporte prioritário por e-mail e telefone.
Programa de desenvolvimento de benchmark
Entre em contato conosco Saiba maisO Benchmark Development Program™ é uma iniciativa da UL Solutions para a construção de parcerias com empresas de tecnologia.
OEMs, ODMs, fabricantes de componentes e seus fornecedores estão convidados a se juntar a nós no desenvolvimento de novos benchmarks de processamento de IA. Entre em contato conosco para mais detalhes.
Requisitos mínimos do sistema
| Sistema Operacional | Android 10 |
|---|---|
| Armazenamento | 400 MB de espaço livre |
Suporte
Versão mais recente 1.0.56 | 27 de novembro de 2020
- Guia do usuário do Benchmark de inferência de IA do Procyon para Android
- Suporte para o Benchmark de inferência de IA para Android
Idiomas
- Inglês