
Procyon® AI Image Generation 

Benchmark der Leistung von GPU AI Image Generation
Der Procyon AI Image Generation Benchmark bietet einen konsistenten, genauen und verständlichen Workload zur Messung der Inferenzleistung von KI-Beschleunigern auf dem Gerät. Dieser Benchmark wurde in Zusammenarbeit mit mehreren wichtigen Branchenmitgliedern entwickelt, um sicherzustellen, dass er faire und vergleichbare Ergebnisse für jegliche unterstützte Hardware liefert.
Der Benchmark umfasst drei Tests zur Messung der Leistung von NPUs mit geringer Leistung bis hin zu High-End-Grafikkarten. The Stable Diffusion XL test is our most demanding AI inference workload, and only the latest high-end GPUs meet the minimum requirements to run it. For moderately powerful discrete GPUs, we recommend the Stable Diffusion 1.5 test. Finally, we designed the Stable Diffusion 1.5 Light test for low power devices using NPUs for AI workloads.
Der Procyon AI Image Generation Benchmark kann so konfiguriert werden, dass es eine Auswahl verschiedener Inferenz-Engines verwendet. Standardmäßig verwendet er die empfohlene optimale Inferenz-Engine für die Hardware des Systems.
Merkmale
- Problemloses Setup und einfache Nutzung über die Procyon-Anwendung oder die Befehlszeile.
Supported Inference Engines
- NVIDIA® TensorRT™
- Qualcomm® QNN
- Intel® OpenVINO™
- ONNX with Microsoft® DirectML
- ONNX + RyzenAI
- Apple® Core ML®
Details des Benchmarks
Stable Diffusion, das im Jahr 2022 erstmals veröffentlicht, hat die Verwendung von KI für die Text-zu-Bild-Erzeugung auf ihrer eigenen Hardware für den normalen Verbraucher zugänglich gemacht. Aufgrund der einfachen Zugänglichkeit, der breiten Nutzung und des kreativen Aspekts wurde die Text-zu-Bild-Erstellung schnell zu einem der einprägsamsten KI-Anwendungsfälle für die Öffentlichkeit.
Der AI Image Generation Benchmark verwendet eine Reihe von standardisierten Textaufforderungen für einen zuverlässigen und konsistenten KI-Bilderzeugungs-Workload. Die Ergebnisse bieten eine Gesamtbewertung für einen einfachen Vergleich sowie weitere detaillierte Bewertungen und die generierten Bilder für eine genauere Prüfung von Leistung und Qualität.
| Test | Workload | Bildauflösung | Stapelgröße | Schritte |
|---|---|---|---|---|
| Stable Diffusion XL | Heavy | 1024 x 1024 | 1 | 100 |
| Stable Diffusion 1.5 | Medium | 512 x 512 | 4 | 100 |
| Stable Diffusion 1.5 Light | Light | 512 x 512 | 1 | 50 |
Ergebnisse und Erkenntnisse
Benchmark-Scores
Vergleichen Sie die Leistung von KO-Inferenz mit zwei verschiedenen Versionen des Stable Diffusion-Modells.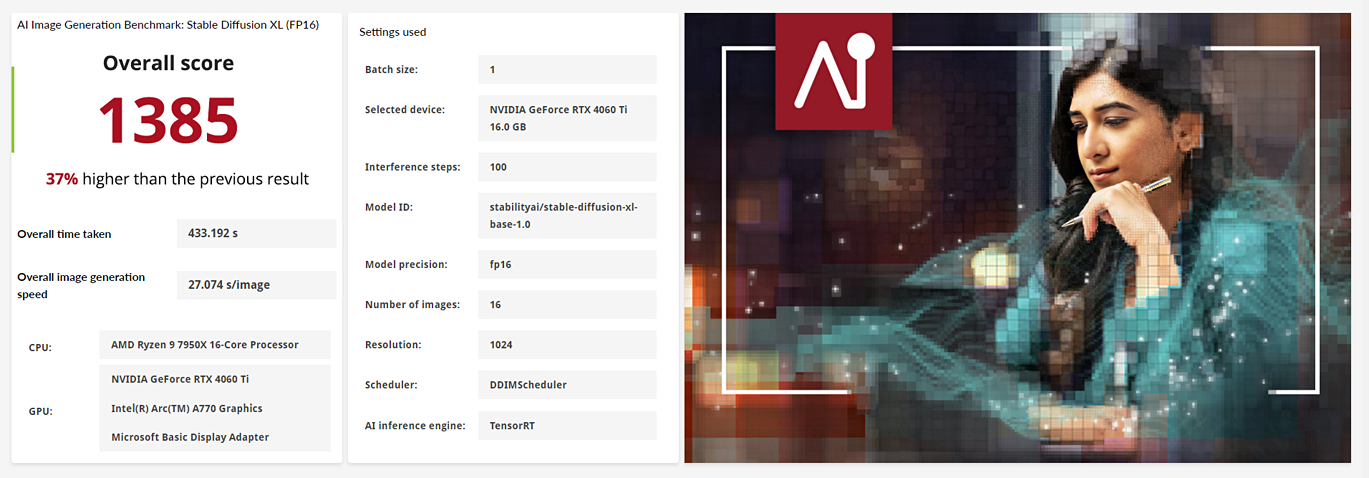
Detaillierte Scores
Prüfen Sie die generierten Bilder und erhalten Sie detaillierte Bewertungen für jeden Bilderzeugungsstapel.
Hardware-Überwachung
Während des Benchmark-Durchlaufs erhalten Sie detaillierten Metriken dazu, wie Temperaturen, Taktfrequenzen und die Nutzung von CPU und GPU sich verändern.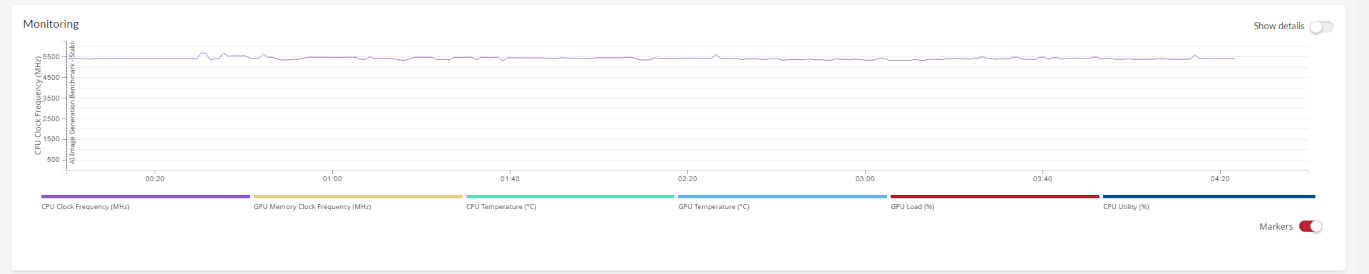
Entwickelt mit Branchenfachkenntnissen
Procyon Benchmarks sind für den Einsatz in Industrie, Unternehmen und Presse konzipiert, mit Tests und Funktionen, die speziell für professionelle Anwender erstellt wurden. Der Procyon AI Image Generation Benchmark wurde zusammen mit Industriepartnern im Rahmen des UL Benchmark Development Program (BDP) konzipiert und entwickelt. Das BDP ist eine Initiative von UL Solutions, die zum Ziel hat, durch enge Zusammenarbeit mit den Programm-Mitgliedern relevante und unparteiische Benchmarks zu schaffen.
Leistung der Inferenzmaschine
Mit dem Procyon AI Image Generation Benchmark können Sie die Leistung dedizierter KI-Verarbeitungshardware messen und die Qualität der Implementierung der Inferenzmaschine anhand von Tests auf der Grundlage eines anspruchsvollen KI-Bilderzeugungs-Workloads überprüfen.
Konzipiert für Fachkräfte
Wir haben unsere Procyon AI Inference Benchmarks für Ingenieurteams entwickelt, die unabhängige, standardisierte Tools zur Bewertung der allgemeinen KI-Leistung von Inferenzmaschinen-Implementierungen und dedizierter Hardware benötigen.
Schnell und einfach zu bedienen
Der Benchmark ist einfach zu installieren und auszuführen, ohne komplizierte Konfiguration. Führen Sie den Benchmark mithilfe der Procyon Anwendung oder über die Befehlszeile aus. Zeigen Sie die Benchmark-Scores und Diagramme an oder exportieren Sie detaillierte Ergebnisdateien zur weiteren Analyse.

Site-Lizenz
Get quote Press license Request trial- Standortjahreslizenz für Procyon AI Image Generation Benchmark.
- Unbegrenzte Anzahl von Benutzern.
- Unbegrenzte Anzahl von Geräten.
- Vorrangiger Support per E-Mail und Telefon
BDP
Kontaktieren Sie uns Mehr erfahrenKontaktieren Sie uns
Das Benchmark Development Program™ ist eine Initiative von UL Solutions zum Ausbau von Partnerschaften mit Technologiefirmen.
OEMs, ODMs, Komponentenhersteller und deren Zulieferer sind eingeladen, gemeinsam mit uns neue Benchmarks für die AI-Verarbeitung zu entwickeln. Bitte kontaktieren Sie uns für Details.
Windows system requirements
| Betriebssystem | Windows 10, 64-bit oder Windows 11 |
|---|---|
| Prozessor | 2 GHz Doppelkern CPU |
| Memory | 16 GB |
| Speicher | 20 GB (75 GB empfohlen) |
MacOS system requirements
| Betriebssystem | macOS Sequoia or later |
|---|---|
| Prozessor | Apple silicon M-Series SoC |
| Memory | 16 GB |
| Speicher | 20 GB (50 GB empfohlen) |
Anforderungen für Stable Diffusion XL
| TensorRT | NVIDIA RTX GPU mit 10 GB VRAM |
|---|---|
| OpenVINO | Diskrete Intel Arc GPU mit 16 GB VRAM |
| ONNX-Laufzeit | 16 GB VRAM |
Anforderungen für Stable Diffusion 1.5
| TensorRT | NVIDIA RTX GPU mit 10 GB VRAM |
|---|---|
| OpenVINO | Diskrete Intel Arc GPU mit 8 GB VRAM oder integrierter Intel GPU mit 32 GB System-RAM |
| ONNX-Laufzeit | 8 GB VRAM (diskrete GPU) – 32 GB RAM (integrierte GPU) |
Stable Diffusion 1.5 Light requirements
| TensorRT | NVIDIA 30 Serie GPU oder höher |
|---|---|
| OpenVINO | Eine Intel NPU, integrierte Intel GPU oder diskrete Intel Arc GPU |
Support
Latest 1.1.265 | 27. Mai 2026
Sprachen
- Englisch
- Deutsch
- Japanisch
- Portugiesisch (Brasilien)
- Simplified Chinese
- Spanisch