
Procyon® AI Text Generation Benchmark 
Vereinfachung der lokalen LLM-KI-Leistungsprüfung
Das Testen der Leistung von KI-LLMs kann sehr kompliziert und zeitaufwändig sein, da vollständige KI-Modelle große Mengen an Speicherplatz und Bandbreite zum Herunterladen benötigen. Bei falscher Konfiguration können viele Variablen wie Quantisierung, Konvertierung und Variationen in den Eingabetokens, die Zuverlässigkeit eines Tests beeinträchtigen.
Procyon AI Text Generation Benchmark bietet eine kompaktere und einfachere Möglichkeit, die KI-Leistung wiederholt und konsistent mit mehreren LLM-KI-Modellen zu testen. Wir haben eng mit vielen führenden Anbietern von KI-Software und Hardware zusammengearbeitet, um sicherzustellen, dass unsere Benchmark-Tests die lokale KI-Beschleuniger-Hardware in Ihren Systemen voll ausschöpfen.
Eingabeaufforderung 7 (RAG-Anfrage): Wie kann Benchmark meiner Organisation helfen, Zeit und Geld zu sparen? Wie wähle ich einen Referenz-Benchmark-Score für Ausschreibungen? Fassen Sie zusammen, wie die Leistung von PCs für die Unternehmens-IT effizient getestet werden kann. Die Antwort basiert auf dem vorgegebenen Kontext.
Ergebnisse und Erkenntnisse
Entwickelt mit der Unterstützung von Branchenführern
- Entwickelt mit Unterstützung führender KI-Anbieter, um die Vorteile der lokalen KI-Beschleuniger-Hardware der nächsten Generation voll auszuschöpfen.
- Sieben Eingabeaufforderungen, die mehrere reale Anwendungsfälle simulieren, mit RAG- (Retrieval-Augmented Generation) und Nicht-RAG-Abfragen
- Erstellt, um konsistente, sich wiederholende Arbeitslasten auszuführen, was zu einer Minimierung häufiger KI-LLM-Arbeitslastvariablen führt.
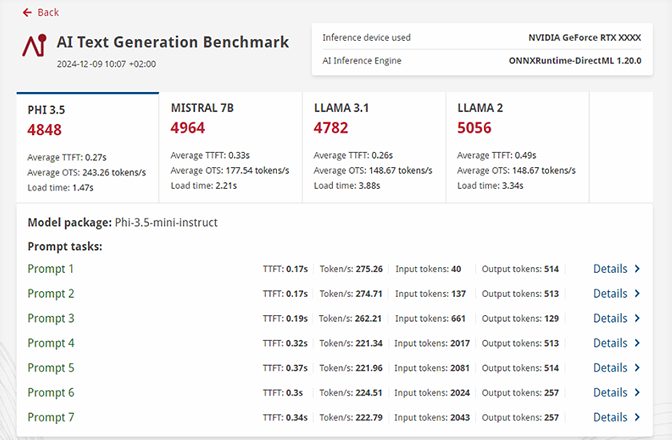
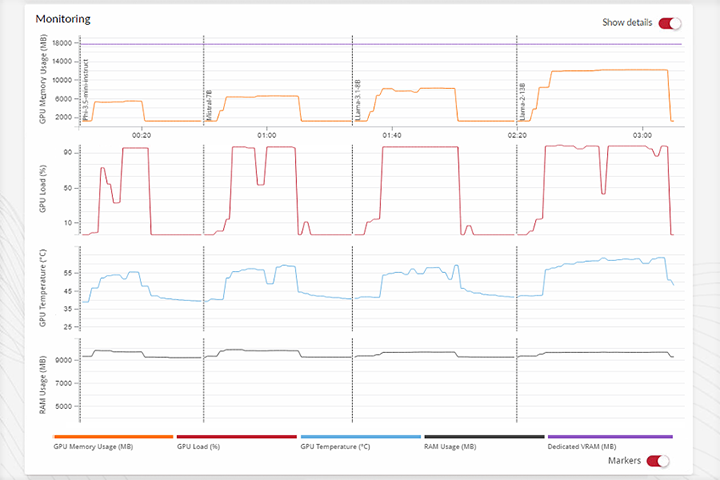
Detaillierte Ergebnisse
- Sie erhalten detaillierte Berichte zur Verwendung von Systemressourcen bei KI-Arbeitslasten.
- Verringert die Installationsgröße gegenüber Tests mit kompletten KI-Modellen.
- Sie können leicht die Ergebnisse der verschiedenen Geräte vergleichen, um herauszufinden, welche Systeme für Ihre konkreten Anwendungsfälle am besten geeignet sind.
Vereinfachte KI-Tests
- Testen Sie einfach und schnell mit vier KI-Modellen verschiedener Parametergrößen nach Industriestandard.
- Sie erhalten einen Echtzeit-Überblick der während des Benchmarks erzeugten Reaktionen.
- Sie haben die Möglichkeit, mit einem einzigen Klick alle unterstützten Inferenzmaschinen zu testen oder diese entsprechend Ihren Vorstellungen anzupassen.
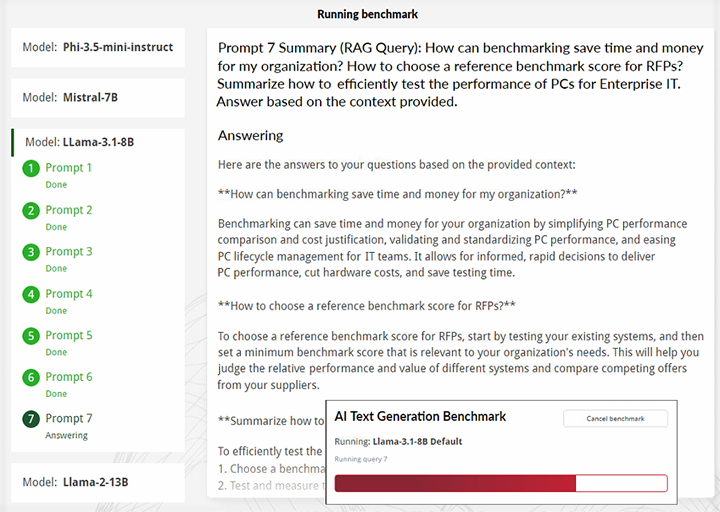
Entwickelt mit Branchenfachkenntnissen
Procyon Benchmarks sind für den Einsatz in Industrie, Unternehmen und Presse konzipiert, mit Tests und Funktionen, die speziell für professionelle Anwender erstellt wurden. Procyon AI Text Generation Benchmark wurde zusammen mit Industriepartnern im Rahmen des UL Benchmark Development Program (BDP) konzipiert und entwickelt. Das BDP ist eine Initiative von UL Solutions, die zum Ziel hat, durch enge Zusammenarbeit mit den Programm-Mitgliedern relevante und unparteiische Benchmarks zu schaffen.
Leistung der Inferenzmaschine
Procyon AI Image Generation Benchmark ermöglicht es, die Leistung dedizierter KI-Verarbeitungshardware zu messen und die Qualität der Implementierung der Inferenzmaschine anhand von Tests zu überprüfen, die auf einer komplexen KI-Bilderzeugungslast basieren.
Konzipiert für Fachkräfte
Wir haben unsere Procyon AI Inference Benchmarks für Ingenieurteams entwickelt, die unabhängige, standardisierte Tools zur Bewertung der allgemeinen KI-Leistung von Inferenzmaschinen-Implementierungen und dedizierter Hardware benötigen.
Schnell und einfach zu bedienen
Der Benchmark ist einfach zu installieren und auszuführen, ohne komplizierte Konfiguration. Führen Sie den Benchmark mithilfe der Procyon Anwendung oder über die Befehlszeile aus. Zeigen Sie die Benchmark-Scores und Diagramme an oder exportieren Sie detaillierte Ergebnisdateien zur weiteren Analyse.
Site-Lizenz
Get quote Press license Request trial- Standortjahreslizenz für Procyon AI Image Generation Benchmark.
- Unbegrenzte Anzahl von Benutzern.
- Unbegrenzte Anzahl von Geräten.
- Vorrangiger Support per E-Mail und Telefon
BDP
Kontaktieren Sie uns Mehr erfahrenDas Benchmark Development Program™ ist eine Initiative von UL Solutions zum Ausbau von Partnerschaften mit Technologiefirmen.
OEMs, ODMs, Komponentenhersteller und deren Zulieferer sind eingeladen, gemeinsam mit uns neue Benchmarks für die AI-Verarbeitung zu entwickeln. Bitte kontaktieren Sie uns für Details.
Systemanforderungen
Alle ONNX Modelle
Speicher 18.25 GB
Alle OpenVINO Modelle
Speicher 15.45 GB
Phi-3.5-mini
- GPU VRAM:
- ONNX 6 GB
- OpenVINO 4 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP/QNN 16 GB
- Speicher
- ONNX 2,15 GB
- OpenVINO 1,84 GB
Llama-3.1-8B
- GPU VRAM:
- ONNX, OpenVINO 8 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP/QNN 32 GB
- Speicher
- ONNX 5,37 GB
- OpenVINO 3,88 GB
Mistral-7B
ONNX mit DirectML
- GPU VRAM:
- ONNX, OpenVINO 8 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP 32 GB
- Speicher
- ONNX 3,69 GB
- OpenVINO 3,48 GB
Llama-2-13B
ONNX mit DirectML
- GPU VRAM:
- ONNX 12 GB
- OpenVINO 10 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO 32 GB
- Speicher
- ONNX 7,04 GB
- OpenVINO 6,25 GB
Support
Latest 1.0.191.0 | 27. Mai 2026
Sprachen
- Englisch
- Deutsch
- Japanisch
- Portugiesisch (Brasilien)
- Simplified Chinese
- Spanisch