
Procyon® AI Inference Benchmark for Android

Benchmark AI performance and quality using NNAPI
Machine learning is powering exciting new features in mobile apps. Many devices now have dedicated hardware to accelerate the computationally intensive operations required for on-device inferencing. The Android Neural Networks API (NNAPI) provides a base layer for machine learning frameworks to access the dedicated AI processing hardware in a device.
The Procyon AI Inference Benchmark for Android measures the AI performance of Android devices using NNAPI. The benchmark score reflects both the speed and the accuracy of on-device inferencing operations. With the Procyon AI Inference Benchmark for Android, not only can you measure the performance of dedicated AI processing hardware in Android devices, you can also verify NNAPI implementation quality.
The benchmark uses a range of popular, state-of-the-art neural networks running on the device to perform common machine-vision tasks. The benchmark runs on the device's dedicated AI-processing hardware via NNAPI. The benchmark also runs each test directly on the GPU and/or the CPU for comparison.
Features
- Tests based on common machine-vision tasks using state-of-the-art neural networks.
- Measures both inference performance and output quality.
- Compare NNAPI, CPU and GPU performance.
- Verify NNAPI implementation and compatibility.
- Optimize drivers for hardware accelerators.
- Compare float- and integer-optimized model performance.
- Simple to setup and use on a device or via ADB.
NNAPI performance and quality
With the Procyon AI Inference Benchmark for Android, you can measure the performance of dedicated AI processing hardware and verify NNAPI implementation quality with tests based on common machine-vision tasks.
Designed for professionals
We created the Procyon AI Inference Benchmark for Android for engineering teams who need independent, standardized tools for assessing the general AI performance of NNAPI implementations and dedicated mobile hardware.
Fast and easy to use
The benchmark is easy to install and run—no complicated configuration required. Run the benchmark on the device or via ADB. View benchmark scores, charts and rankings in the app or export detailed result files for further analysis.
Developed with industry expertise
Procyon benchmarks are designed for industry, enterprise and press use with tests and features created specifically for professional users. The AI Inference Benchmark for Android was designed and developed with industry partners through the UL Benchmark Development Program (BDP). The BDP is an initiative from UL Solutions that aims to create relevant and impartial benchmarks by working in close cooperation with program members.
Neural network models
MobileNet V3

MobileNet V3 is a compact visual recognition model that was created specifically for mobile devices. The benchmark uses MobileNet V3 to identify the subject of an image, taking an image as the input and outputting a list of probabilities for the content in the image. The benchmark uses the large minimalistic variant of MobileNet V3.
Inception V4

Inception V4 is a state-of-the-art model for image classification tasks. Designed for accuracy, it is a much wider and deeper model than MobileNet. The benchmark uses Inception V4 to identify the subject of an image, taking an image as the input and outputting a list of probabilities for the content identified in the image.
SSDLite MobileNet V3
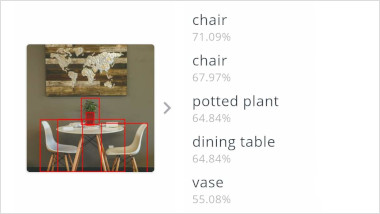
SSDLite is an object detection model that aims to produce bounding boxes around objects in an image. SSDLite uses MobileNet for feature extraction to enable real-time object detection on mobile devices. In the benchmark, the float version of SSDLite uses the small minimalistic MobileNet V3 variant. The integer version uses the EdgeTPU variant of MobileNet V3.
DeepLab V3

DeepLab is an image segmentation model that aims to cluster the pixels of an image that belong to the same object class. Semantic image segmentation labels each region of the image with a class of object. The benchmark uses MobileNet V2 for feature extraction enabling fast inference with little difference in quality compared with larger models.
Custom CNN
The benchmark includes a custom Convolutional Neural Network (CNN) based on the AlexNet architecture. It is designed to test the performance of basic CNN operations and is trained on randomly generated training data. It contains two Convolutional layers, which are followed by Max Pooling and Dropout layers, and one fully connected layer.
Integer and float models
The benchmark includes both float- and integer-optimized versions of each model. Each model runs in turn on all compatible hardware in the device. With NNAPI, the benchmark will use the device's dedicated AI-processing hardware, if supported. Float models use NNAPI or run directly on the CPU or GPU. Integer models use NNAPI or run directly on the CPU.
Results and insights
Benchmark scores
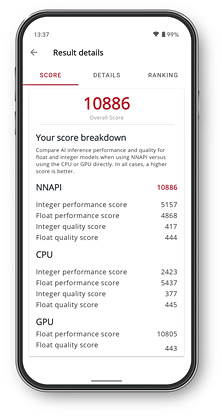
Test devices and processors and compare performance and quality with integer and float models.
Performance charts
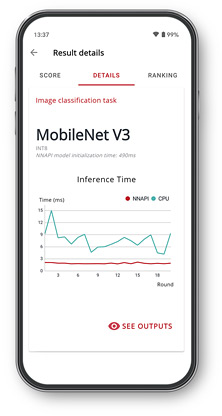
A chart for each model shows the inference time using NNAPI and any other available processors.
Hardware monitoring
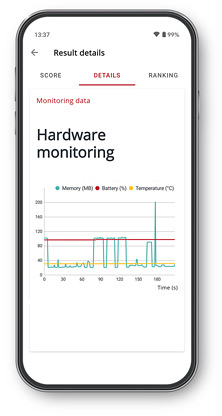
See how temperature, battery charge level, and memory use changed during the benchmark run.
Model outputs
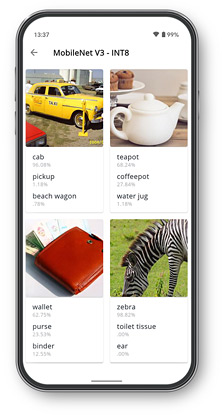
Check the outputs from each model to ensure the accelerator is returning the correct results.
Device ranking
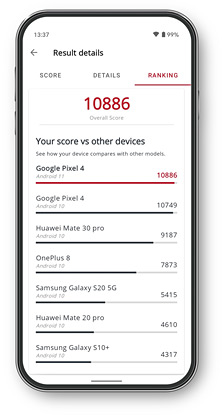
See how your device compares with other models on the in-app performance ranking list.
Site license
Get quote Press license Request trial- Annual site license for Procyon AI Inference Benchmark for Android.
- Unlimited number of users.
- Unlimited number of devices.
- Priority support via email and telephone.
Benchmark Development Program
Contact us Find out moreThe Benchmark Development Program™ is an initiative from UL Solutions for building partnerships with technology companies.
OEMs, ODMs, component manufacturers and their suppliers are invited to join us in developing new AI processing benchmarks. Please contact us for details.
Minimum system requirements
| OS | Android 10 |
|---|---|
| Storage | 400 MB free space |
Support
Latest version 1.0.56 | Nov 27, 2020
Languages
- English