
Procyon® AI Text Generation Benchmark

Simplifying Local LLM AI Performance testing
Testing AI LLM performance can be very complicated and time-consuming, with full AI models requiring large amounts of storage space and bandwidth to download. There are also many variables such as quantization, conversion, and variations in input tokens that can reduce a test’s reliability if not configured correctly.
The Procyon AI Text Generation Benchmark provides a more compact and easier way to repeatedly and consistently test AI performance with multiple LLM AI models. We worked closely with many AI software and hardware leaders to ensure our benchmark tests take full advantage of the local AI accelerator hardware in your systems.
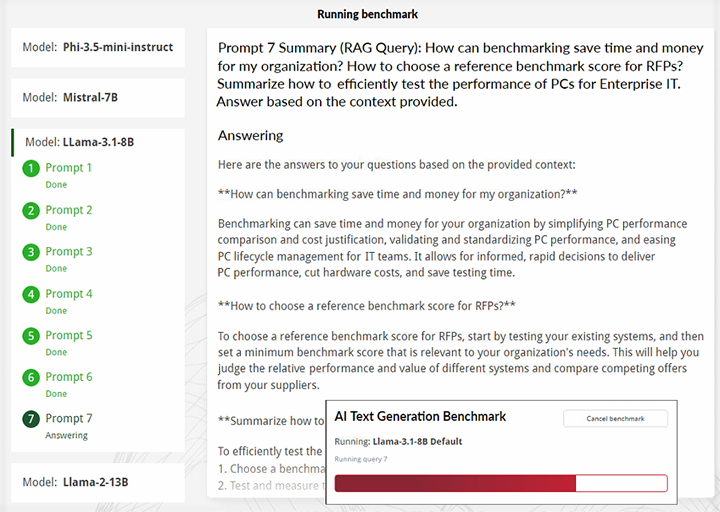
Prompt 7 (RAG Query): How can benchmarking save time and money for my organization? How to choose a reference benchmark score for RFPs? Summarize how to efficiently test the performance of PCs for Enterprise IT. Answer based on the context provided.
Results and insights
Built with input from industry leaders
- Built with input from leading AI vendors to take full advantage of next-generation local AI accelerator hardware.
- Seven prompts simulating multiple real-world use cases, with RAG (Retrieval-Augmented Generation) and non-RAG queries
- Designed to run consistent, repeatable workloads, minimizing common AI LLM workload variables.
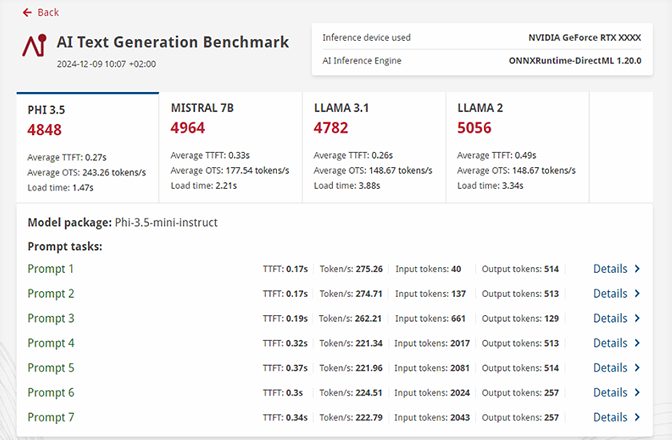
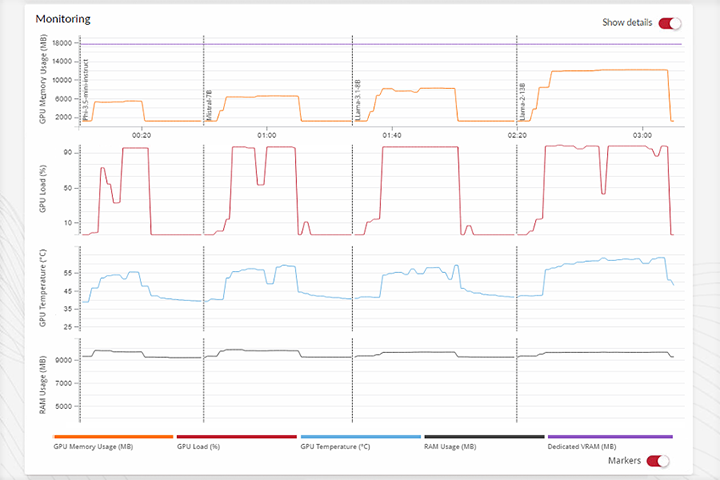
Detailed Results
- Get in-depth reporting as to how system resources are being used during AI workloads.
- Reduced install size vs testing with entire AI models.
- Easily compare results between devices to help identify the best systems for your use cases.
AI Testing Simplified
- Easily and quickly test using four industry standard AI Models of varying parameter sizes.
- Get a real-time view of responses being generated during the benchmark
- One-click to easily test with all supported inference engines, or configure based on your preference.
Developed with Industry expertise
Procyon benchmarks are designed for industry, enterprise, and press use, with tests and features created specifically for professional users. The Procyon AI Text Generation Benchmark was designed and developed with industry partners through the UL Benchmark Development Program (BDP). The BDP is an initiative from UL Solutions that aims to create relevant and impartial benchmarks by working in close cooperation with program members.
Inference Engine Performance
With the Procyon AI Text Generation Benchmark, you can measure the performance of dedicated AI processing hardware and verify inference engine implementation quality with tests based on a heavy AI image generation workload.
Designed for Professionals
We created our Procyon AI Inference Benchmarks for engineering teams who need independent, standardized tools for assessing the general AI performance of inference engine implementations and dedicated hardware.
Fast and easy to use
The benchmark is easy to install and run—no complicated configuration is required. Run the benchmark using the Procyon application or via command-line. View benchmark scores and charts or export detailed result files for further analysis.
Site license
Get quote Press license Request trial- Annual site license for Procyon AI Text Generation Benchmark.
- Unlimited number of users.
- Unlimited number of devices.
- Priority support via email and telephone.
Benchmark Development Program
Contact us Find out moreThe Benchmark Development Program™ is an initiative from UL Solutions for building partnerships with technology companies.
OEMs, ODMs, component manufacturers and their suppliers are invited to join us in developing new AI processing benchmarks. Please contact us for details.
System requirements
All ONNX models
Storage: 18.25 GB
All OpenVINO models
Storage: 15.45 GB
Phi-3.5-mini
- GPU VRAM:
- ONNX 6 GB
- OpenVINO 4 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP/QNN 16 GB
- Storage
- ONNX 2.15 GB
- OpenVINO 1.84 GB
Llama-3.1-8B
- GPU VRAM:
- ONNX, OpenVINO 8 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP/QNN 32 GB
- Storage
- ONNX 5.37 GB
- OpenVINO 3.88 GB
Mistral-7B
ONNX with DirectML
- GPU VRAM:
- ONNX, OpenVINO 8 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO/ORT+VAIP 32 GB
- Storage
- ONNX 3.69 GB
- OpenVINO 3.48 GB
Llama-2-13B
ONNX with DirectML
- GPU VRAM:
- ONNX 12 GB
- OpenVINO 10 GB
- NPU/iGPU RAM:
- ONNX/OpenVINO 32 GB
- Storage
- ONNX 7.04 GB
- OpenVINO 6.25 GB
Support
Latest 1.0.191.0 | May 27, 2026
Languages
- English
- German
- Japanese
- Portuguese (Brazil)
- Simplified Chinese
- Spanish